- October 31st, 2017: Tuesday's #haskell problem has you save off the special characters from yesterday's exercise to a properties file. Today's #haskell solution: properties file created. We also output the special characters in context, which is nice.
- October 30th, 2017: Monday's #haskell problem we contextually find special characters in documents. Whoa! Today's #haskell solution finds that there are a lot of special characters in these documents!
- October 27th, 2017: 2017-10-27, a date where the month/day is an anagram of the year. How many days from today are anagrams of 2017? What are they? Today's #haskell solution: and we have a winner! A bunch of winners, actually for date anagrams in 2017.
- October 26th, 2017: Today's #haskell problem does what Google calls artificial-artificial intelligence analyses on NYT article archives. Today's #haskell solution: from one spreadsheet comes many! Nietzsche would be so proud of me rn.
- October 25th, 2017: Today's #haskell problem, instead of counting articles by topic, we divide articles into browsable/graphable topics. Today's #haskell solution we graph a slice of our NYT article archive.
- October 24th, 2017: Tuesday's #haskell exercise we read back in the articles stored as JSON then partition them by subcategory. Okay! Partitioned articles for today's #haskell solution.
- October 23th, 2017: Monday's #haskell problem we start to analyze our NYT article archive, selecting a topic to dissect. In the #haskell solution we read articles from our data store, then we save them out to file as JSON.
- October 20th, 2017: Today's #haskell problem: NYT article archive through a different lens, as nodes and relations in a graph database. Today's #haskell solution: we wanted #graph we got graph.
- October 19th, 2017: Customer: "Ooh! We love the charts you're making for us, but..." TIL that customers have big 'but's. Today's #haskell solution: And now we can read .gitignore-style configuration files.
- October 18th, 2017: Today's #haskell problem we archive the topics (and article topicality) of the NYT article set. We group data; we regroup data. Ah! The life of a Data Scientist! Today's #haskell solution via @d3js_org #dataviz
- October 17th, 2017: Today's #haskell problem: we build an app that queries the database and generates circle reports. A bit of database work then a bit of JSON to get us our charting tool for today's #haskell solution.
- October 16th, 2017: Thanks to @ahnqir we're looking at cities and skyscrapersfor today's #haskell problem. Ooh! Bar chart! Today's #haskell solution exclaims (proclaims? declaims?) "Look at Hong Kong with its highrises!"
- October 13th, 2017: Yesterday we built a little app (scanner), today we build something a little bigger: a #haskell #ETL application! Today we pull together NYT article parsing and database functions to create a #haskell ETL app! YAY!
- October 12th, 2017: Thursday's #haskell exercise is to build an app named scanner. I, for one, welcome our scanner overlords. Today's #haskell solution is the little scanner app that could!
- October 11th, 2017: Wednesday's #haskell problem: TIL that not all data in production is pristine. SHOCKER! So, okay, we know which document we are in when the less-than-pristine data fandangos on our perfect parser. Good.
- October 10th, 2017:
Boss: "That's a good chart, but can I have it in a spreadsheet?"
me: "But ..."
Boss: "Now."
Today's #haskell solution:
me: Ya wanna spreadsheet, boss? HERE'S YER SPREADSHEET! YA HAPPY?
Boss: um, ... 'yes'?
- October 9th, 2017: Today's #haskell problem asks: can we chart just a few of the topics of the week archive of the NYT? Sure we can! Today's #haskell solution provides the top 5 topics then all topics with 10 or more articles.
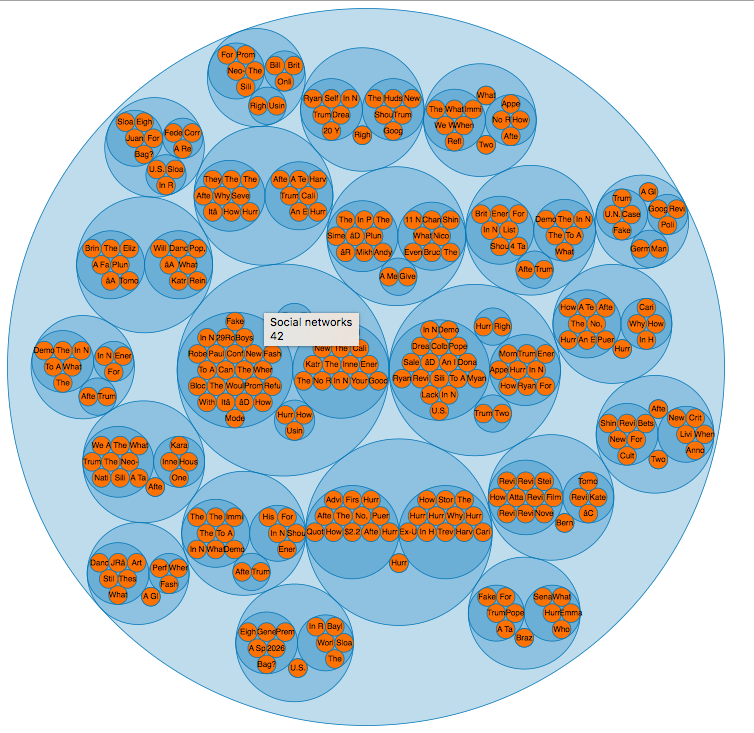
- October 5th, 2017: Friday's #haskell exercise works with data-as-JSON and charting the analyses on the data. Today's #haskell solution has a LOT of circles in its visualization of NYT article topics. A LOT.
- October 4th, 2017: Today's #haskell exercise uses the NYT archive we've stored to look at trending topics and to visualize them. Today's #haskell solution we grab and group data we have in a data store.
- October 3rd, 2017: Building a set of words you key off of in your search for articles? MemoizingTable is today's #haskell problem. We parse a sliced of the NYT article archive and store articles and their respective subjects.
- October 2nd, 2017: Monday's #haskell problem looks at representing SQL join- or pivot-tables generally. Today's solution uses the Pivot values in #haskell to store data on a remote PostgreSQL database.
- September 26th, 2017:
art2RawNames art = Raw (artId art) <$> (Map.lookup "Person" $ metadata art)
curry away the 'art' var. ref: Y2017.M09.D26.Exercise
- September 19th, 2017: The #1Liner to follow (next tweet) is a question based off a code snippet from Y2017.M09.D18.Solution. What is a better/more elegant definition?
fmap (wordStrength . wc) (BL.readFile filename) >>= \dict ->
return (Map.insert filename dict m)
Reformulate. Curry the dict-ref.